Research
Robotics, Machine Learning
2025
-
 A Review of Learning-Based Dynamics Models for Robotic ManipulationBo Ai, Stephen Tian, Haochen Shi, Yixuan Wang, Tobias Pfaff, Cheston Tan, Henrik I. Christensen, Hao Su, Jiajun Wu, and Yunzhu LiScience Robotics, 2025
A Review of Learning-Based Dynamics Models for Robotic ManipulationBo Ai, Stephen Tian, Haochen Shi, Yixuan Wang, Tobias Pfaff, Cheston Tan, Henrik I. Christensen, Hao Su, Jiajun Wu, and Yunzhu LiScience Robotics, 2025Dynamics models that predict the effects of physical interactions are essential for planning and control in robotic manipulation. Although models based on physical principles often generalize well, they typically require full-state information, which can be difficult or impossible to extract from perception data in complex, real-world scenarios. Learning-based dynamics models provide an alternative by deriving state transition functions purely from perceived interaction data, enabling the capture of complex, hard-to-model factors and predictive uncertainty and accelerating simulations that are often too slow for real-time control. Recent successes in this field have demonstrated notable advancements in robot capabilities, including long-horizon manipulation of deformable objects, granular materials, and complex multiobject interactions such as stowing and packing. A crucial aspect of these investigations is the choice of state representation, which determines the inductive biases in the learning system for reduced-order modeling of scene dynamics. This article provides a timely and comprehensive review of current techniques and trade-offs in designing learned dynamics models, highlighting their role in advancing robot capabilities through integration with state estimation and control and identifying critical research gaps for future exploration. Dynamics models learned from real-world interactions with task-aligned representations empower robotic manipulation.
-
 Scaling Cross-Embodiment World Models for Dexterous ManipulationZihao He*, Bo Ai*, Tongzhou Mu, Yulin Liu, Weikang Wan, Jiawei Fu, Yilun Du, Henrik I. Christensen, and Hao SuarXiv, 2025
Scaling Cross-Embodiment World Models for Dexterous ManipulationZihao He*, Bo Ai*, Tongzhou Mu, Yulin Liu, Weikang Wan, Jiawei Fu, Yilun Du, Henrik I. Christensen, and Hao SuarXiv, 2025Cross-embodiment learning seeks to build generalist robots that operate across diverse morphologies, but differences in action spaces and kinematics hinder data sharing and policy transfer. This raises a central question: Is there any invariance that allows actions to transfer across embodiments? We conjecture that environment dynamics are embodiment-invariant, and that world models capturing these dynamics can provide a unified interface across embodiments. To learn such a unified world model, the crucial step is to design state and action representations that abstract away embodiment-specific details while preserving control relevance. To this end, we represent different embodiments (e.g., human hands and robot hands) as sets of 3D particles and define actions as particle displacements, creating a shared representation for heterogeneous data and control problems. A graph-based world model is then trained on exploration data from diverse simulated robot hands and real human hands, and integrated with model-based planning for deployment on novel hardware. Experiments on rigid and deformable manipulation tasks reveal three findings: (i) scaling to more training embodiments improves generalization to unseen ones, (ii) co-training on both simulated and real data outperforms training on either alone, and (iii) the learned models enable effective control on robots with varied degrees of freedom. These results establish world models as a promising interface for cross-embodiment dexterous manipulation.
-
 Towards Embodiment Scaling Laws in Robot LocomotionBo Ai*, Liu Dai*, Nico Bohlinger* , Dichen Li*, Tongzhou Mu , Zhanxin Wu, K. Fay, Henrik I. Christensen, Jan Peters, and Hao SuConference on Robot Learning (CoRL), 2025Abridged in RSS 2025 workshop on Hardware-Aware Intelligence and CoRL 2025 workshop on Robot Data.
Towards Embodiment Scaling Laws in Robot LocomotionBo Ai*, Liu Dai*, Nico Bohlinger* , Dichen Li*, Tongzhou Mu , Zhanxin Wu, K. Fay, Henrik I. Christensen, Jan Peters, and Hao SuConference on Robot Learning (CoRL), 2025Abridged in RSS 2025 workshop on Hardware-Aware Intelligence and CoRL 2025 workshop on Robot Data.Cross-embodiment generalization underpins the vision of building generalist embodied agents for any robot, yet its enabling factors remain poorly understood. We investigate embodiment scaling laws, the hypothesis that increasing the number of training embodiments improves generalization to unseen ones, using robot locomotion as a test bed. We procedurally generate approximately 1,000 embodiments with topological, geometric, and joint-level kinematic variations, and train policies on random subsets. We observe positive scaling trends supporting the hypothesis, and find that embodiment scaling enables substantially broader generalization than data scaling on fixed embodiments. Our best policy, trained on the full dataset, transfers zero-shot to novel embodiments in simulation and the real world, including the Unitree Go2 and H1. These results represent a step toward general embodied intelligence, with relevance to adaptive control for configurable robots, morphology–control co-design, and beyond.
-
 SAVOR: Skill Affordance Learning from Visuo-Haptic Perception for Robot-Assisted Bite AcquisitionConference on Robot Learning (CoRL), 2025Oral Presentation
SAVOR: Skill Affordance Learning from Visuo-Haptic Perception for Robot-Assisted Bite AcquisitionConference on Robot Learning (CoRL), 2025Oral PresentationRobot-assisted feeding requires reliable bite acquisition, a challenging task due to the complex interactions between utensils and food with diverse physical properties. These interactions are further complicated by the temporal variability of food properties—for example, steak becomes firm as it cools even during a meal. To address this, we propose SAVOR, a novel approach for learning skill affordances for bite acquisition—how suitable a manipulation skill (e.g., skewering, scooping) is for a given utensil-food interaction. In our formulation, skill affordances arise from the combination of tool affordances (what a utensil can do) and food affordances (what the food allows). Tool affordances are learned offline through calibration, where different utensils interact with a variety of foods to model their functional capabilities. Food affordances are characterized by physical properties such as softness, moisture, and viscosity, initially inferred through commonsense reasoning using a visually-conditioned language model and then dynamically refined through online visuo-haptic perception using SAVOR during interaction. Our method integrates these offline and online estimates to predict skill affordances in real time, enabling the robot to select the most appropriate skill for each food item. Evaluated on 20 single-item foods and 10 in-the-wild meals, our approach improves bite acquisition success by 13% over state-of-the-art (SOTA) category-based methods (e.g. use skewer for fruits). These results highlight the importance of modeling interaction-driven skill affordances for generalizable and effective robot-assisted bite acquisition.
-
 Enhancing Generalization in Vision-Language-Action Models by Preserving Pretrained Representations2025
Enhancing Generalization in Vision-Language-Action Models by Preserving Pretrained Representations2025Vision-language-action (VLA) models finetuned from vision-language models (VLMs) hold the promise of leveraging rich pretrained representations to build generalist robots across diverse tasks and environments. However, direct fine-tuning on robot data often disrupts these representations and limits generalization. We present a framework that better preserves pretrained features while adapting them for robot manipulation. Our approach introduces three components: (i) a dual-encoder design with one frozen vision encoder to retain pretrained features and another trainable for task adaptation, (ii) a string-based action tokenizer that casts continuous actions into character sequences aligned with the model’s pretraining domain, and (iii) a co-training strategy that combines robot demonstrations with vision-language datasets emphasizing spatial reasoning and affordances. Evaluations in simulation and on real robots show that our method improves robustness to visual perturbations, generalization to novel instructions and environments, and overall task success compared to baselines.
-
 Diffusion Dynamics Models with Generative State Estimation for Cloth ManipulationConference on Robot Learning (CoRL), 2025Abridged in RSS 2025 workshop on Structured World Models for Robotic Manipulation and CoRL 2025 workshop on Learning to Simulate Robot Worlds.
Diffusion Dynamics Models with Generative State Estimation for Cloth ManipulationConference on Robot Learning (CoRL), 2025Abridged in RSS 2025 workshop on Structured World Models for Robotic Manipulation and CoRL 2025 workshop on Learning to Simulate Robot Worlds.Manipulating deformable objects like cloth is challenging due to their complex dynamics, near-infinite degrees of freedom, and frequent self-occlusions, which complicate state estimation and dynamics modeling. Prior work has struggled with robust cloth state estimation, while dynamics models, primarily based on Graph Neural Networks (GNNs), are limited by their locality. Inspired by recent advances in generative models, we hypothesize that these expressive models can effectively capture intricate cloth configurations and deformation patterns from data. Building on this insight, we propose a diffusion-based generative approach for both perception and dynamics modeling. Specifically, we formulate state estimation as reconstructing the full cloth state from sparse RGB-D observations conditioned on a canonical cloth mesh and dynamics modeling as predicting future states given the current state and robot actions. Leveraging a transformer-based diffusion model, our method achieves high-fidelity state reconstruction while reducing long-horizon dynamics prediction errors by an order of magnitude compared to GNN-based approaches. Integrated with model-predictive control (MPC), our framework successfully executes cloth folding on a real robotic system, demonstrating the potential of generative models for manipulation tasks with partial observability and complex dynamics.
-
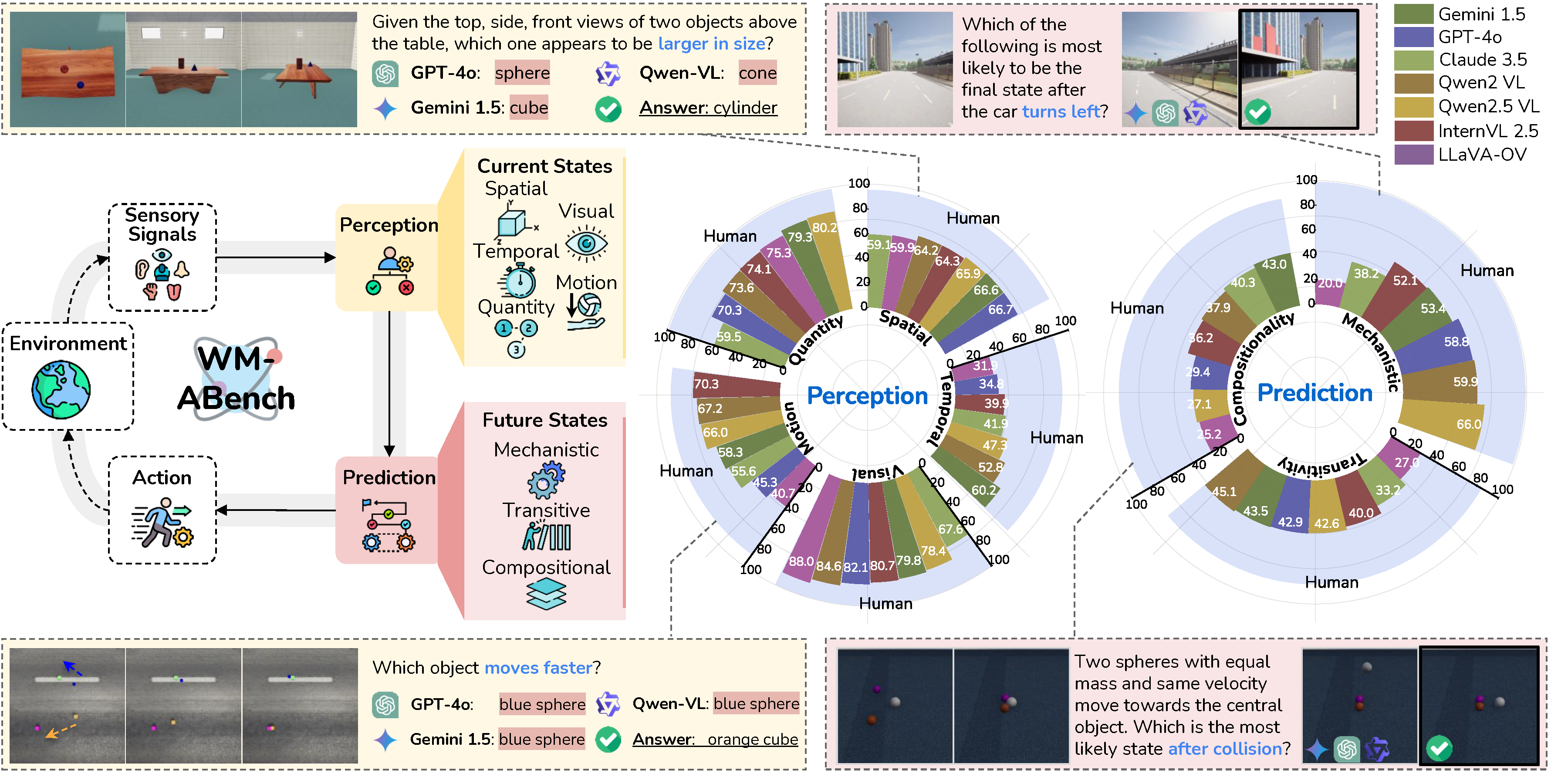 Do Vision-Language Models Have Internal World Models? Towards an Atomic EvaluationQiyue Gao*, Xinyu Pi* , Kevin Liu, Junrong Chen, Ruolan Yang , Xinqi Huang, Xinyu Fang, Lu Sun, Gautham Kishore, Bo Ai, Stone Tao , Mengyang Liu, Jiaxi Yang, Chao-Jung Lai, Chuanyang Jin, Jiannan Xiang , Benhao Huang, David Danks, Hao Su, Tianmin Shu, Ziqiao Ma , Lianhui Qin, and Zhiting HuACL Findings , 2025Abridged in ICLR 2025 workshop on World Models: Understanding, Modelling, and Scaling.
Do Vision-Language Models Have Internal World Models? Towards an Atomic EvaluationQiyue Gao*, Xinyu Pi* , Kevin Liu, Junrong Chen, Ruolan Yang , Xinqi Huang, Xinyu Fang, Lu Sun, Gautham Kishore, Bo Ai, Stone Tao , Mengyang Liu, Jiaxi Yang, Chao-Jung Lai, Chuanyang Jin, Jiannan Xiang , Benhao Huang, David Danks, Hao Su, Tianmin Shu, Ziqiao Ma , Lianhui Qin, and Zhiting HuACL Findings , 2025Abridged in ICLR 2025 workshop on World Models: Understanding, Modelling, and Scaling.Internal world models (WMs) enable agents to understand the world’s state and predict transitions, serving as the basis for advanced deliberative reasoning. Recent large Vision-Language Models (VLMs), such as GPT-4o and Gemini, exhibit potential as general-purpose WMs. While the latest studies have evaluated and shown limitations in specific capabilities such as visual understanding, a systematic evaluation of VLMs’ fundamental WM abilities remains absent. Drawing on comparative psychology and cognitive science, we propose a two-stage framework that assesses Perception (visual, spatial, temporal, quantitative, and motion) and Prediction (mechanistic simulation, transitive inference, compositional inference) to provide an atomic evaluation of VLMs as WMs. Guided by this framework, we introduce WM-ABench, a large-scale benchmark comprising 23 fine-grained evaluation dimensions across 6 diverse simulated environments with controlled counterfactual simulations. Through 517 controlled experiments on 11 latest commercial and open-source VLMs, we find that these models exhibit striking limitations in basic world modeling abilities. For instance, all models perform at near-random accuracy when distinguishing motion trajectories. Additionally, they lack disentangled understanding—e.g., they tend to believe blue objects move faster than green ones. More rich results and analyses reveal significant gaps between VLMs and human-level world modeling.
-
 Learning Adaptive Dexterous Grasping from Single DemonstrationsLiangzhi Shi*, Yulin Liu*, Lingqi Zeng*, Bo Ai, Zhengdong Hong, and Hao SuIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
Learning Adaptive Dexterous Grasping from Single DemonstrationsLiangzhi Shi*, Yulin Liu*, Lingqi Zeng*, Bo Ai, Zhengdong Hong, and Hao SuIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025How can robots learn dexterous grasping skills efficiently and apply them adaptively based on user instructions? This work tackles two key challenges: efficient skill acquisition from limited human demonstrations and context-driven skill selection. We introduce AdaDexGrasp, a framework that learns a library of grasping skills from a single human demonstration per skill and selects the most suitable one using a vision-language model (VLM). To improve sample efficiency, we propose a trajectory following reward that guides reinforcement learning (RL) toward states close to a human demonstration while allowing flexibility in exploration. To learn beyond the single demonstration, we employ curriculum learning, progressively increasing object pose variations to enhance robustness. At deployment, a VLM retrieves the appropriate skill based on user instructions, bridging low-level learned skills with high-level intent. We evaluate AdaDexGrasp in both simulation and real-world settings, showing that our approach significantly improves RL efficiency and enables learning human-like grasp strategies across varied object configurations. Finally, we demonstrate zero-shot transfer of our learned policies to a real-world PSYONIC Ability Hand, with a 90% success rate across objects, significantly outperforming the baseline.








2024
-
 IntentionNet: Map-Lite Visual Navigation at the Kilometre ScaleWei Gao, Bo Ai, Joel Loo, Vinay, and David HsuarXiv, 2024
IntentionNet: Map-Lite Visual Navigation at the Kilometre ScaleWei Gao, Bo Ai, Joel Loo, Vinay, and David HsuarXiv, 2024This work explores the challenges of creating a scalable and robust robot navigation system that can traverse both indoor and outdoor environments to reach distant goals. We propose a navigation system architecture called IntentionNet that employs a monolithic neural network as the low-level planner/controller, and uses a general interface that we call intentions to steer the controller. The paper proposes two types of intentions, Local Path and Environment (LPE) and Discretised Local Move (DLM), and shows that DLM is robust to significant metric positioning and mapping errors. The paper also presents Kilo-IntentionNet, an instance of the IntentionNet system using the DLM intention that is deployed on a Boston Dynamics Spot robot, and which successfully navigates through complex indoor and outdoor environments over distances of up to a kilometre with only noisy odometry.
-
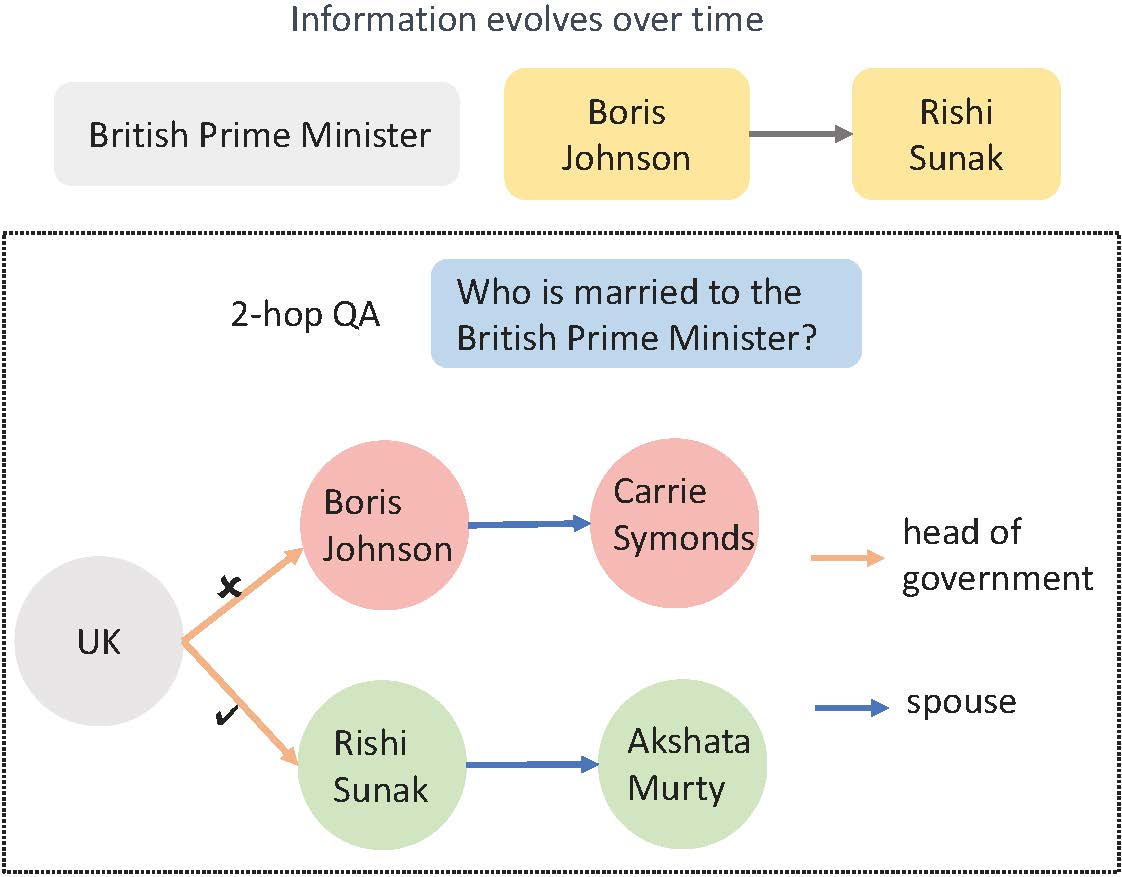 LLM-Based Multi-Hop Question Answering with Knowledge Graph Integration in Evolving EnvironmentsRuirui Chen, Weifeng Jiang, Chengwei Qin, Ishaan Singh Rawal, Cheston Tan, Dongkyu Choi, Bo Xiong, and Bo AiEMNLP Findings, 2024
LLM-Based Multi-Hop Question Answering with Knowledge Graph Integration in Evolving EnvironmentsRuirui Chen, Weifeng Jiang, Chengwei Qin, Ishaan Singh Rawal, Cheston Tan, Dongkyu Choi, Bo Xiong, and Bo AiEMNLP Findings, 2024 -
 RoboPack: Learning Tactile-Informed Dynamics Models for Dense PackingRobotics: Science and Systems (RSS) , 2024Abridged in ICRA 2024 workshops ViTac, 3DVRM, Future Roadmap for Sensorimotor Skills, and RSS 2024 workshop Priors4Robots.
RoboPack: Learning Tactile-Informed Dynamics Models for Dense PackingRobotics: Science and Systems (RSS) , 2024Abridged in ICRA 2024 workshops ViTac, 3DVRM, Future Roadmap for Sensorimotor Skills, and RSS 2024 workshop Priors4Robots.Tactile feedback is critical for understanding the dynamics of both rigid and deformable objects in many manipulation tasks, such as non-prehensile manipulation and dense packing. We introduce an approach that combines visual and tactile sensing for robotic manipulation by learning a neural, tactile-informed dynamics model. Our proposed framework, RoboPack, employs a recurrent graph neural network to estimate object states, including particles and object-level latent physics information, from historical visuo-tactile observations and to perform future state predictions. Our tactile-informed dynamics model, learned from real-world data, can solve downstream robotics tasks with model-predictive control. We demonstrate our approach on a real robot equipped with a compliant Soft-Bubble tactile sensor on non-prehensile manipulation and dense packing tasks, where the robot must infer the physics properties of objects from direct and indirect interactions. Trained on only an average of 30 minutes of real-world interaction data per task, our model can perform online adaptation and make touch-informed predictions. Through extensive evaluations in both long-horizon dynamics prediction and real-world manipulation, our method demonstrates superior effectiveness compared to previous learning-based and physics-based simulation systems.
@inproceedings{ai2024robopack, title = {RoboPack: Learning Tactile-Informed Dynamics Models for Dense Packing}, author = {Ai*, Bo and Tian*, Stephen and Shi, Haochen and Wang, Yixuan and Tan, Cheston and Li, Yunzhu and Wu, Jiajun}, booktitle = {Robotics: Science and Systems (RSS)}, year = {2024}, url = {https://arxiv.org/abs/2407.01418}, note = {Abridged in ICRA 2024 workshops [ViTac](https://shanluo.github.io/ViTacWorkshops/), [3DVRM](https://3d-manipulation-workshop.github.io/), [Future Roadmap for Sensorimotor Skills](https://icra-manipulation-skill.github.io/), and RSS 2024 workshop [Priors4Robots](https://sites.google.com/alora.tech/priors4robots24).} }



2023
-
 Invariance is Key to Generalization: Examining the Role of Representation in Sim-to-Real Transfer for Visual NavigationBo Ai , Zhanxin Wu, and David HsuInternational Symposium on Experimental Robotics (ISER) , 2023Published within Springer Proceedings in Advanced Robotics (SPAR).
Invariance is Key to Generalization: Examining the Role of Representation in Sim-to-Real Transfer for Visual NavigationBo Ai , Zhanxin Wu, and David HsuInternational Symposium on Experimental Robotics (ISER) , 2023Published within Springer Proceedings in Advanced Robotics (SPAR).The data-driven approach to robot control has been gathering pace rapidly, yet generalization to unseen task domains remains a critical challenge. We argue that the key to generalization is representations that are (i) rich enough to capture all task-relevant information and (ii) invariant to superfluous variability between the training and the test domains. We experimentally study such a representation—containing both depth and semantic information—for visual navigation and show that it enables a control policy trained entirely in simulated indoor scenes to generalize to diverse real-world environments, both indoors and outdoors. Further, we show that our representation reduces the A-distance between the training and test domains, improving the generalization error bound as a result. Our proposed approach is scalable: the learned policy improves continuously, as the foundation models that it exploits absorb more diverse data during pre-training.
-
 Integrating Common Sense and Planning with Large Language Models for Room TidyingZhanxin Wu, Bo Ai, and David HsuRSS 2023 Workshop on Learning for Task and Motion Planning , 2023
Integrating Common Sense and Planning with Large Language Models for Room TidyingZhanxin Wu, Bo Ai, and David HsuRSS 2023 Workshop on Learning for Task and Motion Planning , 2023Do you want a personal housekeeper robot? This project seeks to endow robots with the capability of tidying up messy rooms with brief natural language descriptions of the environment. We address three key challenges: (i) incomplete map information in the description, (ii) commonsense understanding of object locations, and (iii) long-horizon planning and acting to achieve the objective. To tackle these challenges, we leverage Large Language Models’ (LLMs) understanding of typical layouts of human-living environments and object locations, as well as programming and control skills for action execution. Specifically, we prompt ChatGPT to reconstruct complete map representations from partial descriptions, then generate a high-level action plan in the form of Python functions, and finally refine the plans with atomic actions executable by the robot. We show that our framework enables effective room rearrangement with limited human instruction guidance. On simulation and real-world maps, it is able to find a place missing out from human description within three interactions with humans. In the simulation environment, it is capable of putting more than 80% household objects in their desired place. This study provides preliminary evidence that LLMs have common sense about the spatial layout of human-living environments and object arrangements, and this work connects this knowledge to robotics tasks.
@inproceedings{wu2023integrating, title = {Integrating Common Sense and Planning with Large Language Models for Room Tidying}, author = {Wu, Zhanxin and Ai, Bo and Hsu, David}, booktitle = {RSS 2023 Workshop on Learning for Task and Motion Planning}, year = {2023}, url = {https://openreview.net/forum?id=vuSI9mhDaBZ}, }


2022
-
 Deep Visual Navigation under Partial ObservabilityBo Ai , Wei Gao, Vinay, and David HsuInternational Conference on Robotics and Automation (ICRA) , 2022
Deep Visual Navigation under Partial ObservabilityBo Ai , Wei Gao, Vinay, and David HsuInternational Conference on Robotics and Automation (ICRA) , 2022How can a robot navigate successfully in rich and diverse environments, indoors or outdoors, along office corridors or trails on the grassland, on the flat ground or the staircase? To this end, this work aims to address three challenges: (i) complex visual observations, (ii) partial observability of local visual sensing, and (iii) multimodal robot behaviors conditioned on both the local environment and the global navigation objective. We propose to train a neural network (NN) controller for local navigation via imitation learning. To tackle complex visual observations, we extract multi-scale spatial representations through CNNs. To tackle partial observability, we aggregate multi-scale spatial information over time and encode it in LSTMs. To learn multimodal behaviors, we use a separate memory module for each behavior mode. Importantly, we integrate the multiple neural network modules into a unified controller that achieves robust performance for visual navigation in complex, partially observable environments. We implemented the controller on the quadrupedal Spot robot and evaluated it on three challenging tasks: adversarial pedestrian avoidance, blind-spot obstacle avoidance, and elevator riding. The experiments show that the proposed NN architecture significantly improves navigation performance.
@inproceedings{ai2022deep, author = {Ai, Bo and Gao, Wei and Vinay and Hsu, David}, title = {Deep Visual Navigation under Partial Observability}, booktitle = {International Conference on Robotics and Automation (ICRA)}, pages = {9439--9446}, publisher = {{IEEE}}, year = {2022}, url = {https://doi.org/10.1109/ICRA46639.2022.9811598}, doi = {10.1109/ICRA46639.2022.9811598}, timestamp = {Mon, 04 Dec 2023 21:29:46 +0100}, biburl = {https://dblp.org/rec/conf/icra/AiGVH22.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, } -
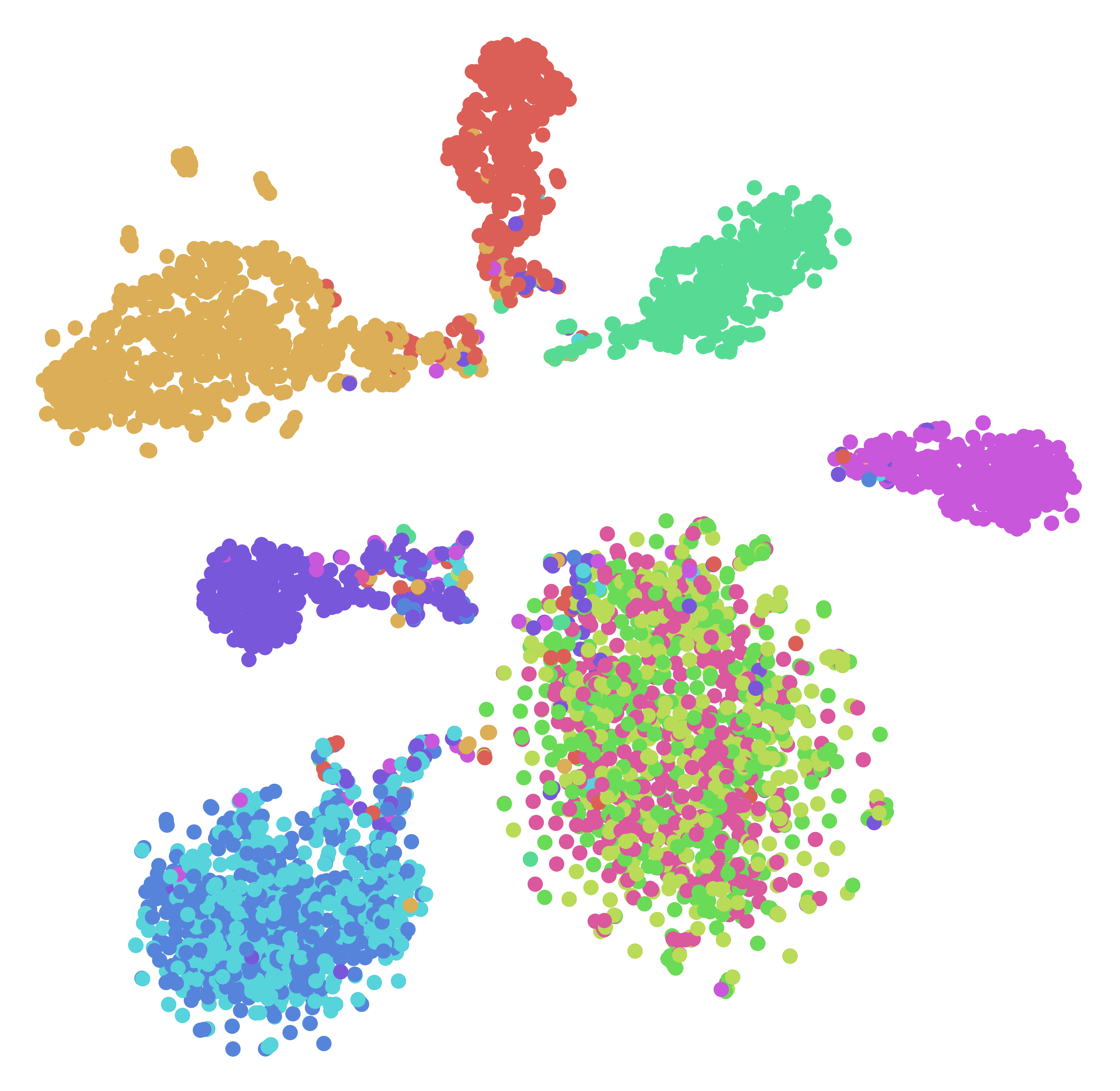 Whodunit? Learning to Contrast for Authorship AttributionBo Ai , Yuchen Wang , Yugin Tan , and Samson TanInternational Joint Conference on Natural Language Processing (IJCNLP) , 2022
Whodunit? Learning to Contrast for Authorship AttributionBo Ai , Yuchen Wang , Yugin Tan , and Samson TanInternational Joint Conference on Natural Language Processing (IJCNLP) , 2022Authorship attribution is the task of identifying the author of a given text. The key is finding representations that can differentiate between authors. Existing approaches typically use manually designed features that capture a dataset’s content and style, but these approaches are dataset-dependent and yield inconsistent performance across corpora. In this work, we propose \textitlearning author-specific representations by fine-tuning pre-trained generic language representations with a contrastive objective (Contra-X). We show that Contra-X learns representations that form highly separable clusters for different authors. It advances the state-of-the-art on multiple human and machine authorship attribution benchmarks, enabling improvements of up to 6.8% over cross-entropy fine-tuning. However, we find that Contra-X improves overall accuracy at the cost of sacrificing performance for some authors. Resolving this tension will be an important direction for future work. To the best of our knowledge, we are the first to integrate contrastive learning with pre-trained language model fine-tuning for authorship attribution.
@inproceedings{ai2022whodunit, author = {Ai, Bo and Wang, Yuchen and Tan, Yugin and Tan, Samson}, editor = {He, Yulan and Ji, Heng and Liu, Yang and Li, Sujian and Chang, Chia{-}Hui and Poria, Soujanya and Lin, Chenghua and Buntine, Wray L. and Liakata, Maria and Yan, Hanqi and Yan, Zonghan and Ruder, Sebastian and Wan, Xiaojun and Arana{-}Catania, Miguel and Wei, Zhongyu and Huang, Hen{-}Hsen and Wu, Jheng{-}Long and Day, Min{-}Yuh and Liu, Pengfei and Xu, Ruifeng}, title = {Whodunit? Learning to Contrast for Authorship Attribution}, booktitle = {International Joint Conference on Natural Language Processing (IJCNLP)}, pages = {1142--1157}, publisher = {Association for Computational Linguistics}, year = {2022}, url = {https://aclanthology.org/2022.aacl-main.84}, timestamp = {Tue, 29 Nov 2022 14:53:03 +0100}, biburl = {https://dblp.org/rec/conf/ijcnlp/AiWTT22.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, }

